
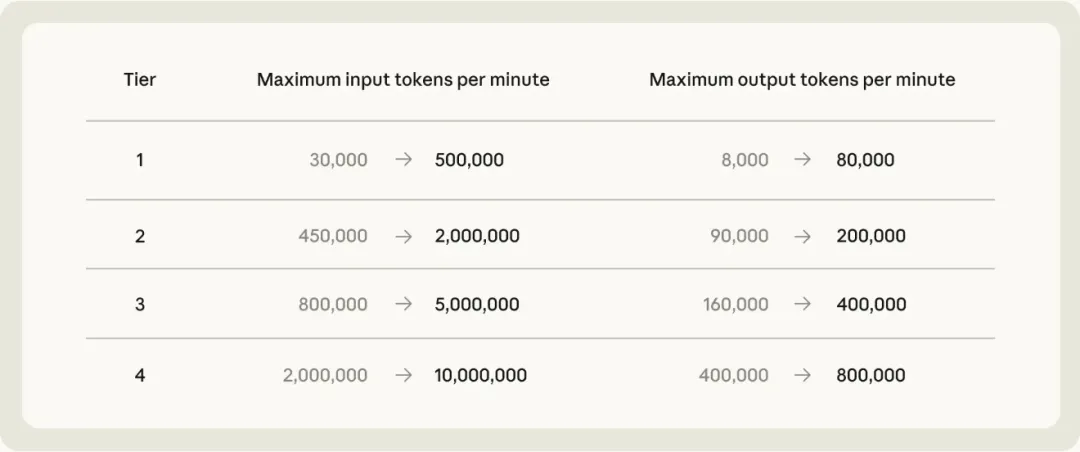
同时 Opus API 的速率上限也大幅提高,开发者能一次性处理更多任务。
之前经常出现的激情 Vibe 一小时,天才程序员陨落的情况也会得到改善
以前 Claude Code 重度用户经常被容量卡住,现在至少5小时窗口明显宽裕,API那边吞吐量上来了,复杂项目也能顺着跑(只要你额度顶得住)。
不过我们回头看看这件事,显然,算力现在已经是AI最核心的资源。
模型再聪明,没有稳定的大规模算力也跑不起来,而建数据中心要电、要地、要冷却、要审批,周期长、成本高。
全球电力供应本来就紧张,AI训练和推理需求又在爆炸式增长,很多地方已经出现“有钱也买不到算力”的情况。
能源和基建成了新的瓶颈。
传统电网扩容慢,送电跟不上,冷却系统越来越吃力。。。地面数据中心越建越大,成本却越来越高。
谁能更快拿到稳定的大规模算力,谁就能在产品体验和用户留存上先一步拉开差距。
Colossus1 本来是 xAI 建的超级集群,现在被 Musk 宣布解散后,通过 SpaceX 这个平台整租给了 Anthropic,xAI 自己已经搬到 Colossus2,SpaceX 就把老集群的容量拿出来换收入,同时帮助 Anthropic 缓解用户端的压力。
直接竞争对手在算力层面实现合作,这在以前的AI圈并不常见。
这个数据中心也是有点故事,2024年仅用122天快速建成

这是今年最大的AI算力交易之一,300MW的Colossus容量让Claude的限额痛点能明显缓解,这种合作对推理容量来说是真正的游戏改变者。
这些变化从今天开始实打实生效。
Anthropic把新增算力直接回馈给付费用户,短期内用户体验提升明显。
长远看,这件事也暴露了AI竞争的真实逻辑——模型能力重要,但基础设施更关键。
算力短缺让原本对立的阵营开始通过租赁、合作来补位。
xAI 被整合进 SpaceX 后,SpaceX 又把算力租给 Anthropic,这种资源流动在2026年已经越来越常见。
未来,SpaceX 还可能和 Anthropic 继续谈轨道数据中心,那种多吉瓦级的规模一旦落地,会把整个行业的算力供给再推高一个量级。
算力为王的时代,Claude再强,也得先解决“电从哪里来、GPU在哪里跑”的问题。
毕竟,模型再强,你得你得有卡来推理,得有电来开机。