
圣何塞McEnery会议中心的GTC 2026开幕式上,已经进行了2小时直播的黄仁勋依然经历旺盛,快步走向被受瞩目的GTC 2026 Keynote主舞台,开启了长达2个半小时的开幕演讲。此刻NVIDIA关于AI的订单量,已经从2025年的5000亿美元,来到了现在的万亿级美元,近乎翻倍的增长也预示了未来一段时间,这家专注生产AI工具的公司,将如何构建未来AI市场的走向。
这时候AI工厂收入将会从两个纬度进行平衡,即使吞吐量(Throughput),每瓦特电力产生的Token数量;智能度(Intelligence),指Token生成速度。这里黄仁勋引用Grace Blackwell作为参考,相比Hopper架构,Blackwell在免费层提升吞吐量35倍,对于高价值的编码、工程推理,性能则可以提升35倍以上。
NVIDIA将2025年称为推理之年,推理是AI计算的终极难点,它将直接决定公司的收入。而推理与训练是由本质区别的。训练是一次性大规模计算,追求峰值算力。推理是持续性、低延迟、高并发服务,追求每美元Token成本和每瓦特Token产出。
为实现极致推理效率,NVIDIA开发了Dynamo AI工厂操作系统,能够轻松在Vera Rubin和Groq之间智能调度任务,支持万亿参数模型的KV Cache管理和多层级服务品质(QoS)的混合部署。
有意思的是,Token也延伸出新的经济学和企业预算科目,未来每家企业都同时是Token消费者和Token制造商,这意味着企业即自己消耗Token,同时也通过Token对外提供服务。
Token也带来了计算范式的根本转变,旧范式的检索式计算本质上是存储已有信息,按需调用,通过数据库查询、文件系统、网页浏览来实现。AI新范式则是直接生成答案而非检索,每次查询都涉及实时推理、合成、创造,这解释了为何计算需求呈百万倍增长,AI不是在查找信息,而是在思考答案。
面对万亿美元级别的AI基础设施投资,黄仁勋强调NVIDIA架构的核心优势在于,NVIDIA是唯一支持AI全生命周期(训练、后训练、推理)的平台,同时NVIDIA也是唯一同时支持语言、生物学、计算机图形、物理仿真、机器人等多模态AI的架构的公司。
Vera Rubin架构:下一代AI基础设施
接下来就是黄仁勋的带货环节。Vera Rubin并非简单的芯片升级,而是针对Agentic AI工作负载的端到端系统重构。黄仁勋强调,传统数据中心架构已无法满足AI代理的需求,Agentic AI的三大系统压力,包括思考计算(Thinking)、内存墙(Memory Wall)和工具(Tool)的使用问题。
新生的AI应用带来了大语言模型规模持续膨胀,进而需要生成更多Token,这对算力有很高的要求。KV Cache、结构化数据(cuDF)、非结构化数据(cuVS)对存储系统则是对内存墙产生了绝大的压力。与此同时,AI需要以极快速度访问工具,包括浏览器、虚拟PC、数据库等等,合适的工具也同等重要。
Vera Rubin厉害的地方在于,将计算、内存、网络、冷却、供电整合为单一巨型系统,通过端到端协同优化实现物理极限性能,以解决传统数据中心架构无法满足Agentic AI系统范式所带来的压力。
目前Agentic AI的系统压力可以分成三个:
思考计算(Thinking):大语言模型规模持续膨胀,需要生成更多Token且速度更快;
内存墙(Memory Wall):KV Cache、结构化数据cuDF、非结构化数据cuVS对存储系统造成了成吨的压力;
工具使用(Tool Use):AI需要以极快速度访问工具,包括浏览器、虚拟PC、数据库等场景。AI应用场景中,工具越快的被调用,体验就越好。
顺带一提,Agentic AI虽然也可以翻译成智能体AI或者代理式AI,但与PC端的AI智能体小龙虾不同,前者为AI系统架构,后者为具体的落地应用。
Vera Rubin单一巨型系统,即第六代NVLink 72使用了100%的45℃温水液冷设计,通过冷却液直接将热量带走,无需复杂的空调系统设计。同时由于省略的铜缆设计,通过预配置连接,服务器的安装时间从2天压缩到了2小时。
与之前Grace Hopper一样,Vera为专用CPU的代号,这是NVIDIA首次推出专为AI优化的数据中心CPU,也是全球唯一使用LPDDR5内存的数据中心CPU,在低功耗表现上会亮眼很多。通过提升CPU单线程性能,AI工具也能获得更快的响应速度,配合超高I/O带宽,处理AI Agent智能体的频繁数据访问请求也更为轻松。
当然搭配72个 Vera Rubin,并非NVLink 72的极限。通过Spectrum-X共封装光学(CPO)交换机设计,将光学器件直接封装在交换机芯片上,电子信号直接转换成光信号,无需外部光模块,同时也可以将NVLink扩展至576个GPU,即NVLink 576。
一旦涉及海量GPU部署,一套合适的机架就显得相当重要了。相对于标准的Vera Rubin只需要传统的水平划入式机架,双GPU组合的Vera Rubin Ultra需要Kyber机架支持,GPU会垂直插入,最多支持144个GPU,从而实现单域NVLink 144。
再多的Rubin GPU,这套AI超算还是有物理极限的。特别是当AI服务需要超高频Token生成完成实时编码、高频交易或者交互式AI的时候,GPU架构本身并不能完成低延迟解码,这是大规模并行架构本身缺陷决定的。这时候就需要专门优化单线程Token生成速度作为确定性数据流架构弥补空缺,Groq应运而生。
Groq团队属于谷歌TPU团队离职后的二次创业,虽然名义上是独立运作公司,但目前通过NVIDIA资产收购和人才收购,在2025年末实现了与NVIDIA深度绑定。

Vera Rubin成为了首个融入Groq并实现任务解耦的平台。Rubin负责预处理、Attention计算和KV Cache存储任务,适合高吞吐矩阵计算和大容量HBM内存环境使用。Groq负责Decode Token生成、低延迟推理,在确定性数据流、超大SRAM和静态编译调度中使用。NVIDIA会通过Dynamo操作系统对两者进行调度。
Groq的静态编译调度消除了GPU的动态开销,也很好的突破了内存墙,突破万亿参数模型的物理限制,通过Groq的存储模型权重,用SRAM完成权重的快速访问。这样的收益是非常明显的,相比纯Rubin GPU计算,Groq加入之后可以获得35倍的性能提升。通过专用的以太网络,两者的协同延迟可以降低50%。
在部署策略上,黄仁勋建议AI工厂可以考虑75%为Vera Rubin用来处理高吞吐工作负载,剩下的25%为Groq,用来处理高价值、低延迟任务。Groq加入是NVIDIA从训练、吞吐转向全Spectrum推理的关键一步,无论是经济、技术还是系统层面,都是非常重要的。目前Groq LP30由三星代工打造,在2026Q3就会大规模出货。与此同时,Groq LP40也已经在NVIDIA参与下开发,下一代Feynman架构将由GPU、Groq LP40、Rosa CPU、Blue Field DPU和CX10存储平台实现,并同时支持铜缆扩展和共封装光学扩展,从而实现NVLink 144和NVLink 576大规模GPU集群扩展。

黄仁勋表示,目前NVIDIA已经能够支持万亿美元级基础设施的供应链,每周可生产数千个机架系统,相当于每月可以生产出数个GigaWatts级别功耗的AI工厂,GB300机架还能与Vera Rubin机架并行生产,可根据供需调整,相互之间不会因此影响产能。
从数字到物理世界
黄仁勋明确讲AI智能体(AI Agent)分成了两种形态,一种是数字智能体(Digital Agents),在数字世界中感知、推理和行动,比如编写代码、处理数据;另一种是物理智能体(Physical Agents),也就是机器人在物理世界中感知、推理和行动。
后者的物理AI(Physical AI)需要理解物理定律,比如重力、摩擦力、材料特性等等。因此物理AI需要处理真实世界的海量多样性、不可预测性和边缘情况,这是在虚拟世界不存在的不确定因素。海量的物理特性不可能仅依靠真实数据训练,必须依赖合成数据生成和高保真仿真,这也是物理AI的核心。

目前NVIDIA已经为机器人产业构建了完整的端到端基础设施,包括负责训练计算的NVIDIA DGX、Cosmos世界模型;负责合成数据生成与仿真的Isaac Lab、Omniverse;以及机器人嵌入式Jetson Thor,实现机器人内部的实时推理。
这时候自动驾驶成为了物理AI的首个大规模落地场景。NVIDIA与Robotaxi-Ready平台合作,在比亚迪、日产、捷豹路虎、本次、丰田、通用帮助下,现在已经具备每年生产1800万辆Robotaxi的能力,通过与Uber合作,可以将多个城市的出租车网络接入其中,快速构建一套适合自动驾驶物理AI的应用场景。
在现场,黄仁勋展示了通过NVIDIA Alvin解释车辆自动驾驶过程中的决策过程,让自动驾驶变得更有逻辑可言。在CES2026上,这套运作方式已经成功让奔驰测试车型轻松穿梭在旧金山的都市街道中。
自动驾驶仅是其中之一。在工业机器人和制造业领域,物理AI能够涵盖ABB、卡特彼勒这样的种公羊,在富士康这样的电子制造行业中,通过Isaac Lab微调GROOT模型用于产线,或者使用Isaac Lab进行训练和数据生成,亦或者使用Isaac Lab和Cosmos生成手术室辅助机器人训练数据,让医疗机器人成为可能。
物理AI甚至可以通过仿真平台解决数据难题,因为真实世界数据永远无法覆盖所有场景,AI生成数据+物理仿真到时有机会解决这一点。
因此NVIDIA构建了三项技术给物理AI提供支持,即Isaac Lab、Cosmos 世界模型和GR00T 开放机器人基础模型。
Isaac Lab是一套开源、可扩展、GPU加速的可微分物理仿真平台,开发者可预训练世界基础模型,使用互联网规模视频和人类演示,Isaac Lab本身也支持经典仿真和神经仿真混合使用,能够与Cosmos世界模型和很好的融合,最终生成大规模合成数据和训练策略。
Cosmos 世界模型则用于神经仿真(Neural Simulation),生成符合物理规律的虚拟环境,用于替代传统基于规则的物理引擎,AI学习物理世界的内在规律。
GR00T则是开放的机器人推理与动作生成模型,类似LLM的功能,负责理解指令、规划动作、控制执行。这是NVIDIA推出的全球首个开放式人形机器人基础模型(Foundation Model),旨在为通用人形机器人提供推理和控制能力,被黄仁勋称为"机器人领域的ChatGPT时刻"。
本质上,GR00T是一个视觉-语言-动作(VLA)模型,能够理解自然语言指令、感知视觉环境,并生成精确的机器人动作。其架构设计灵感源自人类认知的双系统理论,系统一为快速动作模型,负责直觉式的反应和实时控制,系统二为慢速推理模型,基于视觉语言模型(VLM)进行深思熟虑的决策。模型通过扩散变换器(Diffusion Transformer)头部对连续动作进行降噪处理,将高层指令转化为低层机械控制信号。
在2025年3月份,NVIDIA发布了首个版本GR00T N1,目前版本是GR00T N1.7,并计划在今年底升级到GR00T N2。GR00T通过结合多种数据来源以解决真实机器人数据稀缺的问题,同时能够加入阵营中的机器人数量越多自然越好。在GTC 2026现场展示了110款对应的机器人,涵盖了全球范围内的所有主要机器人制造商。同时也包括了人形机器人、工业机器人臂、自主移动机器人和迪士尼娱乐机器人。
迪士尼娱乐机器人自然是最令人深刻的,与之前展示R2D2不同,这一次NVIDIA展示了与与迪士尼合作的Olaf雪宝。这是一套完全在NVIDIA Omniverse中使用Newton物理求解器训练出来的机器人,机器人通过物理仿真学习行走,然后零样本迁移到真实世界。同时由于基于物理的仿真,Olaf能适应真实世界的物理特性。NVIDIA Omniverse虽然销量不及预期,但从目前来看,依然是NVIDIA希望推动的重点产品之一。
构建开放模型
黄仁勋在现场阐述了NVIDIA一套独特的双轨制AI策略,在在垂直整合硬件基础设施的同时,AI模型是水平开放的,各行各业都可以基于开放模型微调,构建符合本地数据隐私和文化背景的专属AI,NVIDIA目标仍然是卖出更多的硬件,而非在AI模型上构建壁垒。
为此,NVIDIA发布了一系列特定的开放模型,包括通用推理与语言模型Nemotron 3,物理世界仿真Cosmos 2,生物化学与分子设计BioNIMO,以及用于气候与天气预测的Earth 2。
目前Nemotron 3已经在关键基准测试中达到世界顶尖水平,擅长的领域包括研究推理、语音模型、世界模型以及通用机器人和自动驾驶推理。同时Nemotron 3分成三个版本,包括基础版的Nemotron 3,面向超大规模应用的Nemotron 3 Ultra,以及与AI Agent框架真整合的Nemotron 3 OpenClaw版。
这里黄仁勋盛赞了OpenClaw龙虾对计算机史带来的里程碑的转变,仅发布的几周内就达到了Linux 30年才能获得成就,并且已经比肩HTML和Linux开源软件成为同等重要的基础设施级软件。通过简单命令行即可下载、构建、部署AI智能体,并且可灵活添加工具、数据源和自定义能力,也可以与NVIDIA硬件和软件栈深度优化。
针对AI工厂,NVIDIA还推出了名为NVIDIA NeMo云框架,这是一套融合了硬件层、库与工具层以及生态集成层的架构,包含了Vera Rubin架构的优化部署,cuDF、cuVS加速库,以及Dynamo推理操作系统。通过对Vera Rubin的优化,这套方式可以更好的确保Token生成效率,并支持机密计算,确保模型与数据安全。
黄仁勋认为,Token已成为硅谷人才竞争的核心筹码,并且企业也将扮演Token消费者和制造者,不仅为员工购买AI算力提升生产力,同时也产生Token对外提供服务。AI智能体将扮演企业级IT转型,原本供人使用的工具将被特定领域的专业化智能体替代。AI智能体像云服务API那般被租赁。
企业计算与数据平台重构
数据类型可以分成结构化数据和非结构化数据。黄仁勋认为这两类企业数据资产在AI时代都将被重构。结构化数据是业务运营的基础,传统CPU数据处理系统已无法跟上AI智能体的访问速度,NVIDIA cuDF(CUDA Data Frames)无疑是利用GPU加速结构化数据库处理的理想解决方案。
同样,非结构化数据现在已经占据全球年生成数据的90%,但几乎无法被有效利用,原因是缺乏索引机制,必须理解含义和目的才能查询。NVIDIA给出的解决方案是利用NVIDIA cuVS(CUDA Vector Search)GPU加速的语义向量搜索库,从而完成对非结构化数据的处理。简单的说,cuDF与cuVS构建了NVIDIA对结构化数据和非结构化数据两套GPU加速的组合拳。
其中cuDF进行的结构化数据AI加速擅长企业ERP、供应链、财务数据的实时分析,与IBM合作案例显示5倍速度提升,83%成本降低。cuVS非结构化数据检索用于PDF文档理解、视频内容检索、语音转文本分析,将非结构化数据嵌入为高维向量,支持快速语义相似性搜索。
cuDF与cuVS目前已经在IBM、DELL、Google Cloud、亚马逊云、Microsoft Azure、Oracle、CoreWeave、Telstra + Dell等企业中展开应用。AI时代下,传统的检索式将被生成式替代,数据访问本身是新内容的生产,并由AI智能体与人类进行交互,围绕GPU加速构建的计算框架,成本不会收到摩尔定律影响,而是随着加速计算得到不断优化。
金融服务、医疗保健、零售业与安全计算很快就会率先受到影响,通过cuDF和cuVS两大基础库,NVIDIA正在将传统上由CPU主导的数据处理(占企业IT支出的核心部分)迁移到GPU加速架构,实现结构化与非结构化数据的统一AI化访问,标志着企业IT从检索式工具使用向生成式智能体的范式转移,这不仅是技术升级,更是涉及万亿美元IT支出的产业重构。
写在最后:构建全新的生态与行业
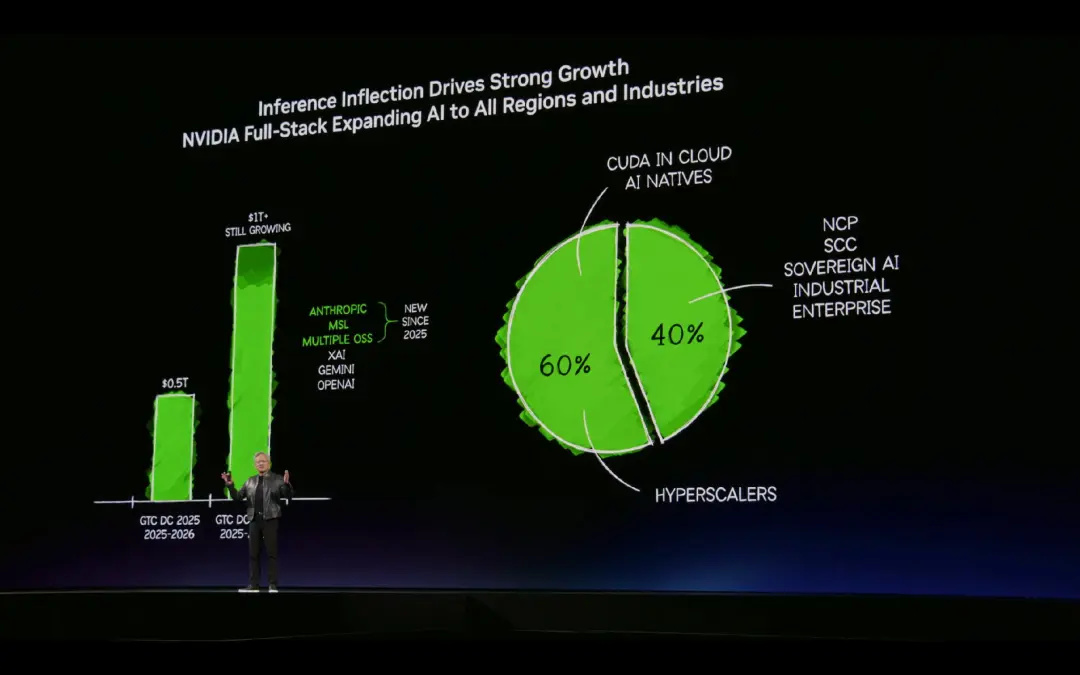
黄仁勋表示,目前NVIDIA业务已经呈现出了双金字塔结构,其中60%来自超大规模云服务商,推荐系统从传统表格和协同过滤开始转向深度学习大模型,传统搜索则开始转向深度学习大模型,同时基于NVIDIA生态构建出来的原生AI公司也越来越多。
另外40%来自多样化的长尾市场,应用场景遍布工业机器人、边缘计算、超算、小型服务器。AI不是单一应用的技术,而是跨行业的基础设施。
同时黄仁勋也强调了CUDA的二十年生态带来的飞轮效应,从便于部署到算法突破,加速了整个生态系统的正向循环。基于CUDA生态的硬件几乎应用于每个云平台、每个计算机公司、每个行业,软件资产包含数十万公开项目,数千工具、编译器、框架和库。从台积电芯片制造商,到服务器OEM、再到云服务商和AI应用公司,哪怕是拥有150年历史的公司,在全新的AI浪潮中也创造了全新的营收纪录,足以见得AI对行业的重要性。
随着行业的垂直程度加深,数万亿美元的产业将会迎来重构。比如金融服务的量化交易从人工特征工程、经典机器学习转向超算自动发现数据模式;医疗保健通过AI完成新药物发现、诊断代理、客户服务,药物分子模拟变得轻而易举。
NVIDIA深耕十年的制造业与机器人行业,现在也正在迈向训练、仿真、边缘计算的体系,NVIDIA已经与几乎全球机器人展开了合作,GTC2026现场的110个机器人就是很好的例子。在零售端,AI可以很好的完成供应链优化、购物系统、客服支持,NVIDIA构建了一套完整的端到端智能零售技术栈。
在电信领域,基站从单一信号传输转向AI基础设施平台,基站将成为机器人化无线电塔,将具备推理和自适应能力,目前NVIDIA合作伙伴诺基亚、T-Mobile已经率先展开部署。最后是媒体、娱乐和游戏,AI已经被应用于直播翻译、广播支持、实时游戏增强。RTX、Holoscan用于实时视频处理。
基于AI的原生企业开始迎来自己的高光时刻,AI初创公司的风险投资历史性爆发,现在已经出现了从百万到十亿级美元的投资跨度,每家公司都需要海量计算和Token,要么自建Token工厂,要么在现有Token上增值,类似于Google、Amazon、Meta级别的公司很可能在原生AI初创公司中诞生。
这样的结论并非一拍脑袋得出的,黄仁勋将GTC 2025和GTC 2026订单规模进行了对比。GTC 2026期间,NVIDIA获得了5000亿美元的订单规模,而在当下,GTC 2026将带来上万亿美元的订单,增长速度翻倍。在未来,AI从训练转向推理,每家企业都需要AI工厂,Agentic AI将会提供7×24小时不间断的推理服务,自动驾驶、机器人等物理世界AI均需要AI边缘计算作为基础设施。
在长达两个半小时的GTC 2026演讲中,黄仁勋展示了一套万亿美元级AI经济闭环的AI生态系统,从上游芯片供应链到下游行业应用,从超大规模云到主权边缘部署,从20年历史的CUDA开发者社区到新兴的AI原生独角兽。NVIDIA不仅成为AI基础设施的提供者,更是全球AI产业生态的枢纽节点,其影响已超越单纯的技术供应商,正在重塑全球计算产业的经济结构和权力分布。