省流总结一下:
Metal0间距通过SAQP继续做小,成本爆炸,但是Lg不依赖EUV微缩起来困难,N+3 CPP= 57nm,与台积电 N6 相当,再往下若无EUV几乎碰壁,n+4还有一点空间,压单元高度、压M2到SAQP、CPP微缩到54nm(intel7),如果达到198nm的height和54nm的cpp,n+4密度应该能到137.8 MTr/mm,但每一步的边际成本和复杂度都在爆炸,没有EUV的话,平面微缩往下做会越来越不划算,SA估算的n+5革新引入背部供电,最终做到高170nm,cpp53nm,密度163.6 MTr/mm,大致能与英特尔18A工艺的高性能库处于同一水平,已经是极限中的极限了,最终实现起来的难道可想而知,所以转向逻辑折叠也是面对EUV光刻设备缺失这一现实约束所给出的系统性解决方案。
必须客观指出,中国目前并未缩小与英特尔、三星和台积电之间的整体技术差距。本次拆解在多个维度上呈现了相反的事实:没有EUV光刻、没有背面供电技术、更高的工艺复杂性,以及处处可见的性能取舍。
但同样真实的是:中国仍然在前进。出口管制并未终结中国半导体产业的演进,EUV光刻设备的禁运提高了尖端制造环节的成本与复杂度,但并未使其停滞,SMIC通过DUV浸入、SAQP和DTCO达到N6级逻辑密度已经向我们证明了这点

小结:对于华为而言,目前最有前途的并不是手机,而是计算卡和服务器市场的商业采购,赶巧的是,这两者要的是规模是晶体管密度而不是频率。这也注定了密度才是华为目前追求的第一选项。大家想赛博斗蛐蛐的建议不要在频率和峰值功耗上下注,因为注定在这几年内看不到太多的进步。
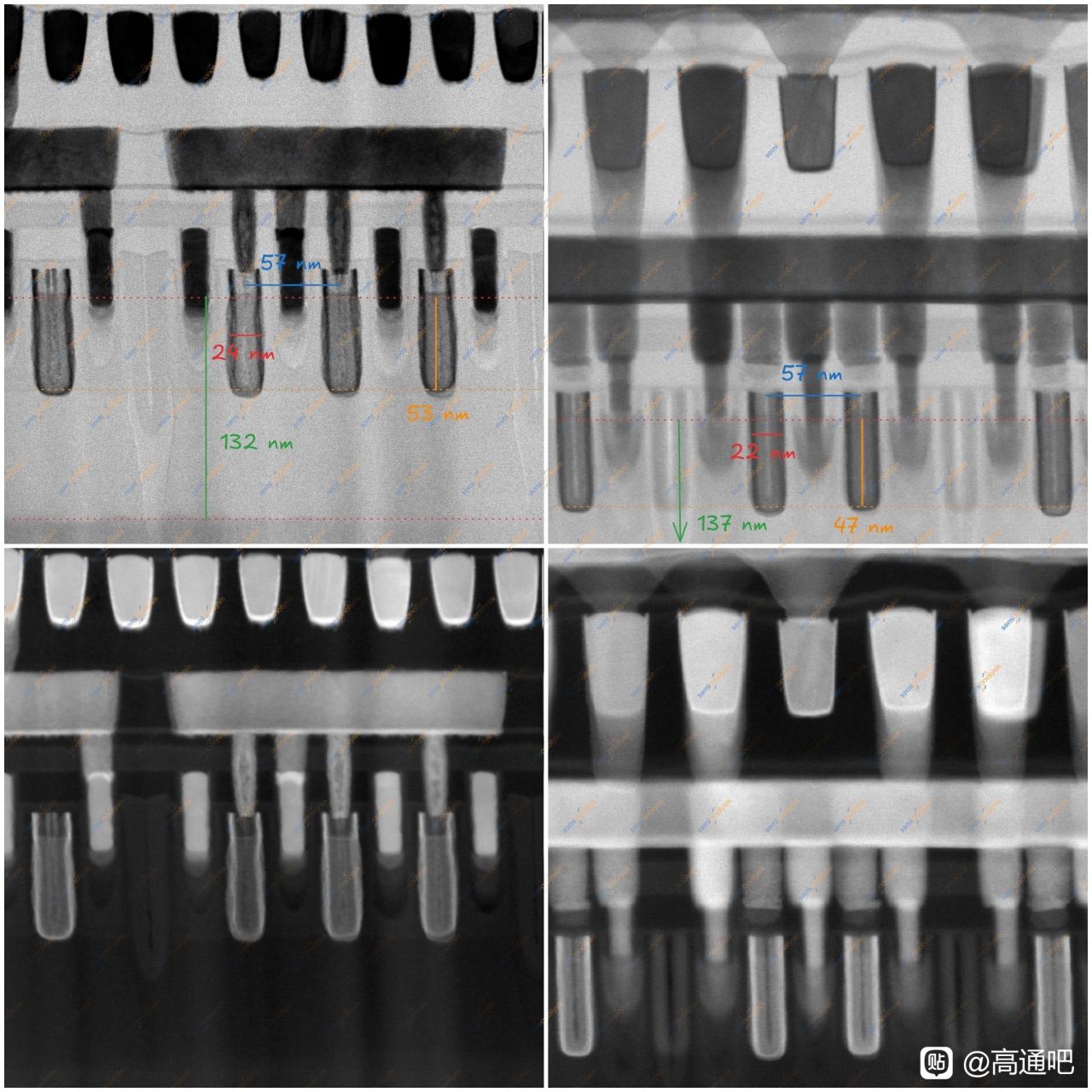
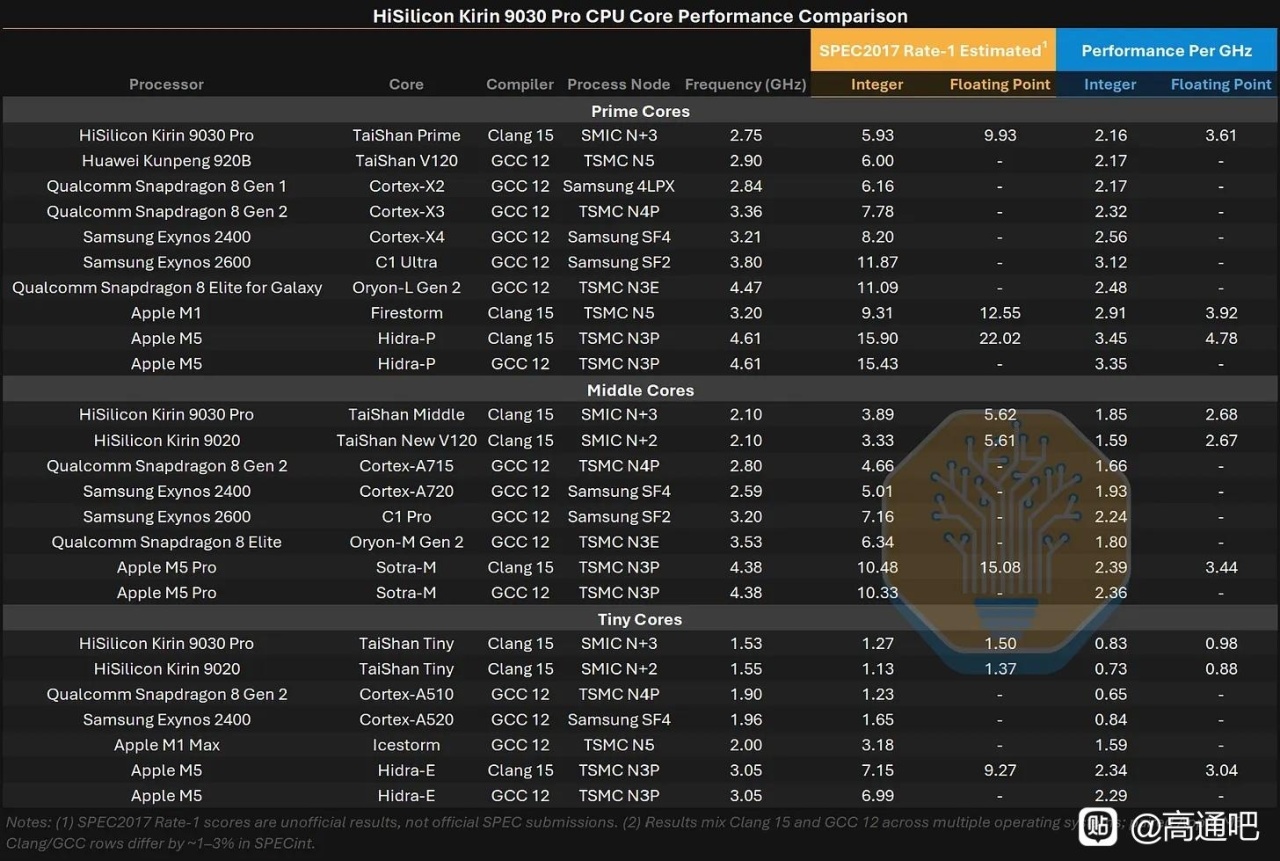
两年前我的看法是N+3将会把CPP缩小到57nm,其中Lg=20nm Wc=18nm,在TEM下我们看到CPP确实降到了57nm,Lg也到了20nm(图上的测量24nm是错的,不必理会),Wc比想像更激进些做到了16nm,当然这也说明Tsp带来的寄生电阻确实给SMIC带来了不小的麻烦。这些都基中预测中了,N+3确实能称之为7nm级别的制程了。

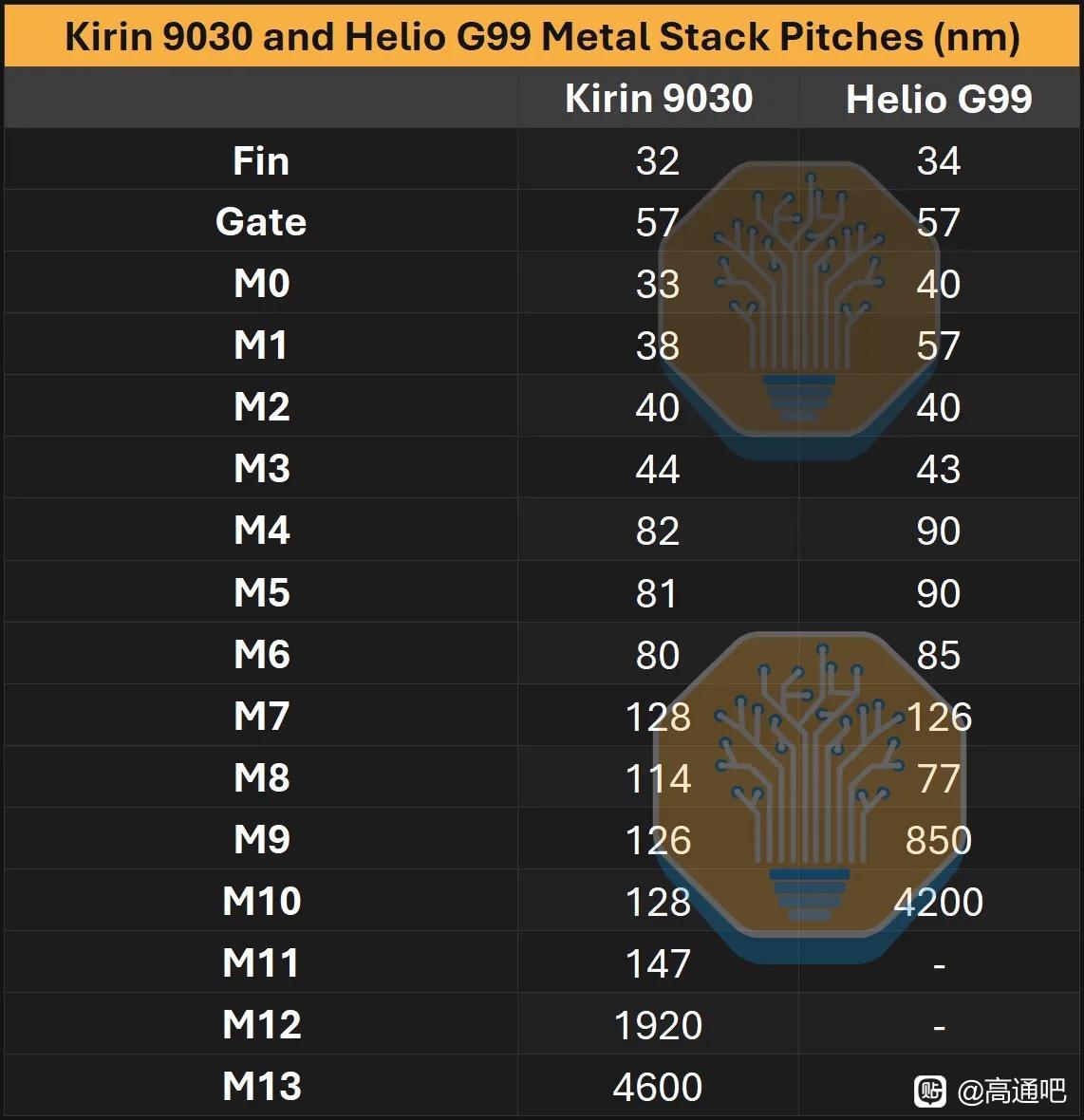
M2P=32,M0=30确实没在我的预测内,SMIC选了一个很激进的玩法,用30nm的M0做一个7.6T的HD库。原本按照我的想法,M2P=40 HD库为6T,CH=240,完美复刻tsmc N7,但显然,,SMIC并没有照我想的去实现,它将布线密度拉高,将金属层数做大,处处透露着四个大字:节约面积。

从gate切面的角度你能看出DUV控制CPP大小的艰难:在四重曝光下gate length 上下差值有4nm之多,误差超过20%,工艺角和体质方差你可想而知,所以我坚持认为在EUV没投产的N+4 CPP将会保持57nm不变。其次,堆叠为面积松了绑,2+1fin不再是下一代的追求,我认为30nm M0+6T的HD库CH=180nm将是SMIC冲击的重点,即我认为N+4的晶体管尺寸为G57H180,密度提升27%。
SemiAnalysis 的核心判断是:SMIC N+3 m 不是“真正赶上 Intel/TSMC 领先节点”,而是用非常激进的 DUV 多重图形化 + DTCO,把平面逻辑密度推到 TSMC N6 级别附近。N+3 已用于华为 Kirin 9030,是 SMIC 第三代 7nm 级工艺;它的最小本地金属 M0 pitch 为 32.5 nm,表面上甚至小于 Intel Panther Lake 上 18A 已量产版本的 36 nm M0 pitch,但作者强调这是一个“片面的指标”,因为 M0 只是 cell 内局部互连层,不能代表整个工艺节点的 PPA、良率、成本、互连完整性和设计灵活性。
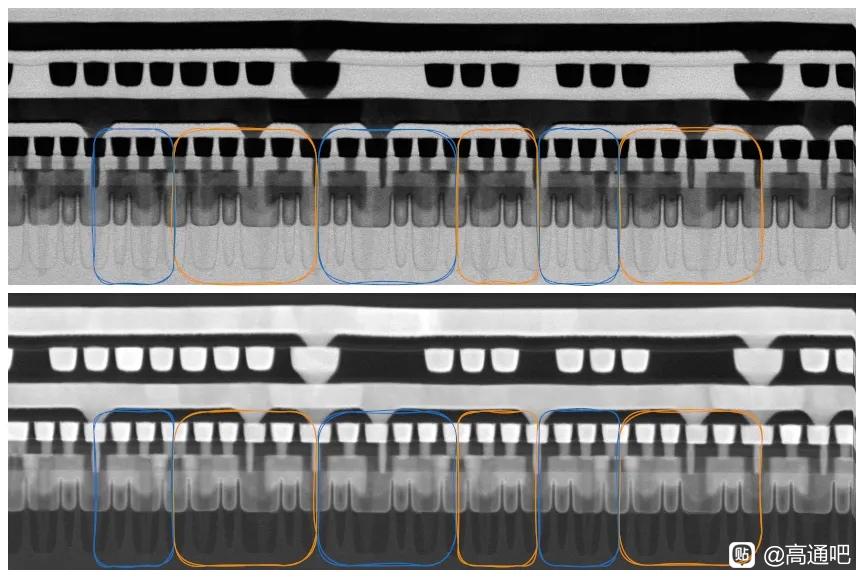
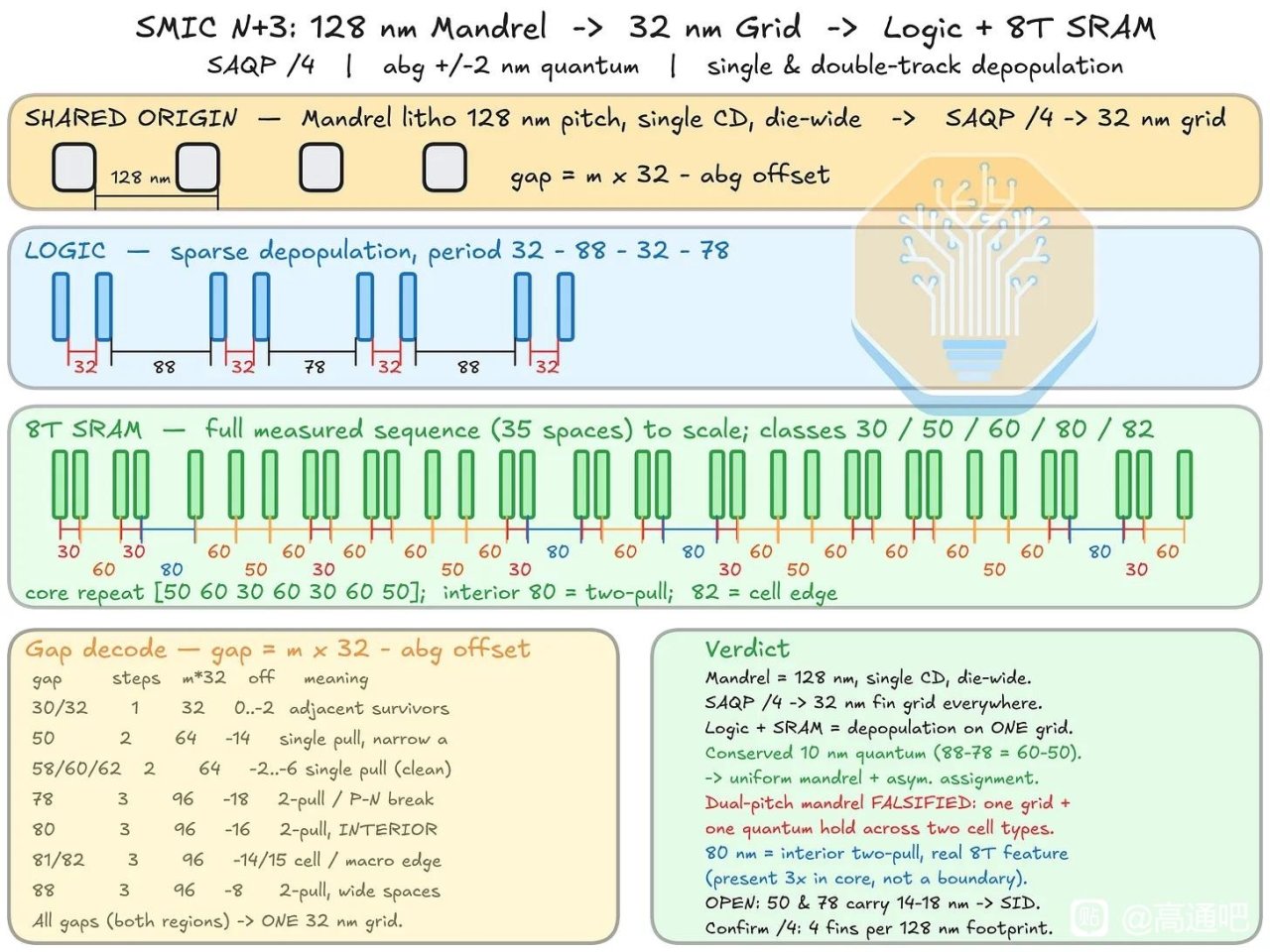
从晶体管层看,N+3 仍是 FinFET,不是 GAA。文章用 Kirin 9030 与 TSMC N6 的 Helio G99 做 TEM 横截面对比,测得 N+3 fin pitch 约 30–32 nm,TSMC N6 样本约 34 nm;N+3 可能通过 128 nm mandrel + SAQP 形成全芯片约 32 nm 的 fin grid。它的 fin 更高、更窄,aspect ratio 约 9.5:1,高于 N6 的 7.8:1,顶部圆角也更小。这说明 SMIC 在 FEOL 几何形貌上确实推得很激进,但这种更高纵横比、更紧 pitch 的 fin 也会带来刻蚀、线边粗糙、器件变异和良率控制压力。
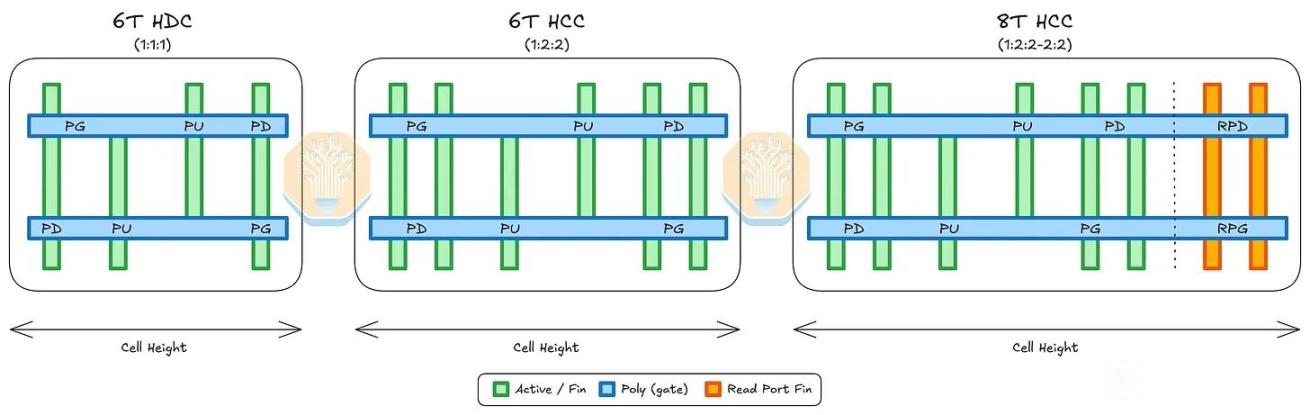
标准单元方面,N+3 的 cell height 为 228 nm,比 TSMC N6 HD cell 的 240 nm 小约 5%,也比 SMIC N+2 的 252 nm 缩小约 9.5%;CGP 为 57 nm,与 TSMC N6 HD 相同。关键是 SMIC 把一系列 density booster 都用上了:fin depopulation,即每个 NMOS/PMOS 只用 2 根 fin;COAG,即 contact over active gate,把 gate contact 放到 active gate 上方压缩 cell;以及 SDB,即 single diffusion break,用面积换取更高的局部效应建模/工艺控制难度。SemiAnalysis 用 Bohr metric 估算 N+3 逻辑晶体管密度约 113.4 MTr/mm²,略高于 TSMC N6 的 107.7 MTr/mm²。作为参照,TSMC 官方也说明 N6 使用更多 EUV 层来提高工艺简单性、周期和生产率,而 SMIC N+3 则是在没有 EUV 的约束下靠 DUV 多重图形化和 DTCO 达到接近密度。
互连层是最关键的部分。N+3 的 M0 pitch = 32.5 nm,比 N+2 和 N6 缩小约 19%,需要 SAQP;M1 pitch 为 38 nm,M2 pitch 为 40 nm,M3 pitch 为 44 nm。文章认为 M0 小于 Panther Lake 上的 Intel 18A 量产 M0 pitch 是事实,但不代表 SMIC N+3 比 Intel 18A 先进,因为 Intel 18A 有 RibbonFET GAA、PowerVia 背面供电等结构性优势,而 N+3 仍是传统正面供电 FinFET。Intel 官方也把 18A 的核心差异化定义为 RibbonFET + PowerVia,而非单个金属 pitch 指标。
N+3 的 M1/gate 比例也很有意思:SMIC N+2/N+3 使用 3:2 M1-to-gate ratio,而 TSMC N6 是 1:1。3:2 的好处是局部布线更灵活,能缓解标准单元内 power/signal crossing 的压力;坏处是版图网格和多重图形化更复杂,对 PDK、EDA 和 overlay 控制要求更高。换句话说,SMIC 不是靠 EUV 简化流程,而是反过来用更复杂的 DUV 分割、更多 mask、更多工艺控制难度去换密度。
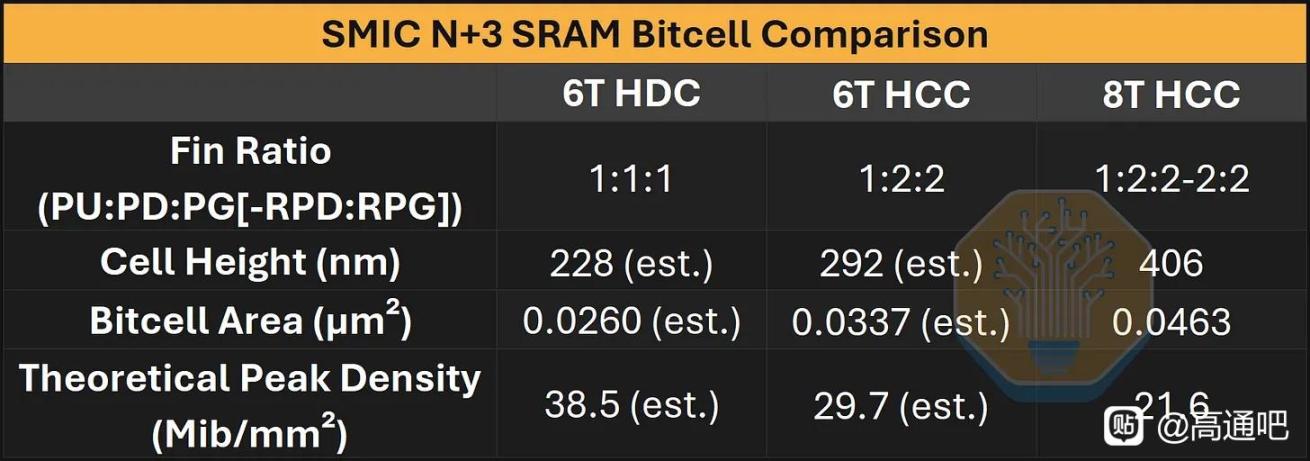
SRAM方面,文章发现了 8T SRAM,其 bitcell 为 0.0463 µm²,理论峰值密度 21.6 Mib/mm²;估算 6T high-density cell 可到 0.0260 µm²、理论 38.5 Mib/mm²,大致接近 Samsung 7LPP/5LPP,略低于 TSMC N7/N6。实际缓存宏方面,Kirin 9030 相比 Kirin 9020 的 SLC/L3/L2 阵列面积约缩小 17–18%,整体 SRAM scaling 约 19%。但作者也提醒,N+2 的 SRAM bitcell 原本偏大,所以这部分既有真正缩小,也有“补课式追赶”。

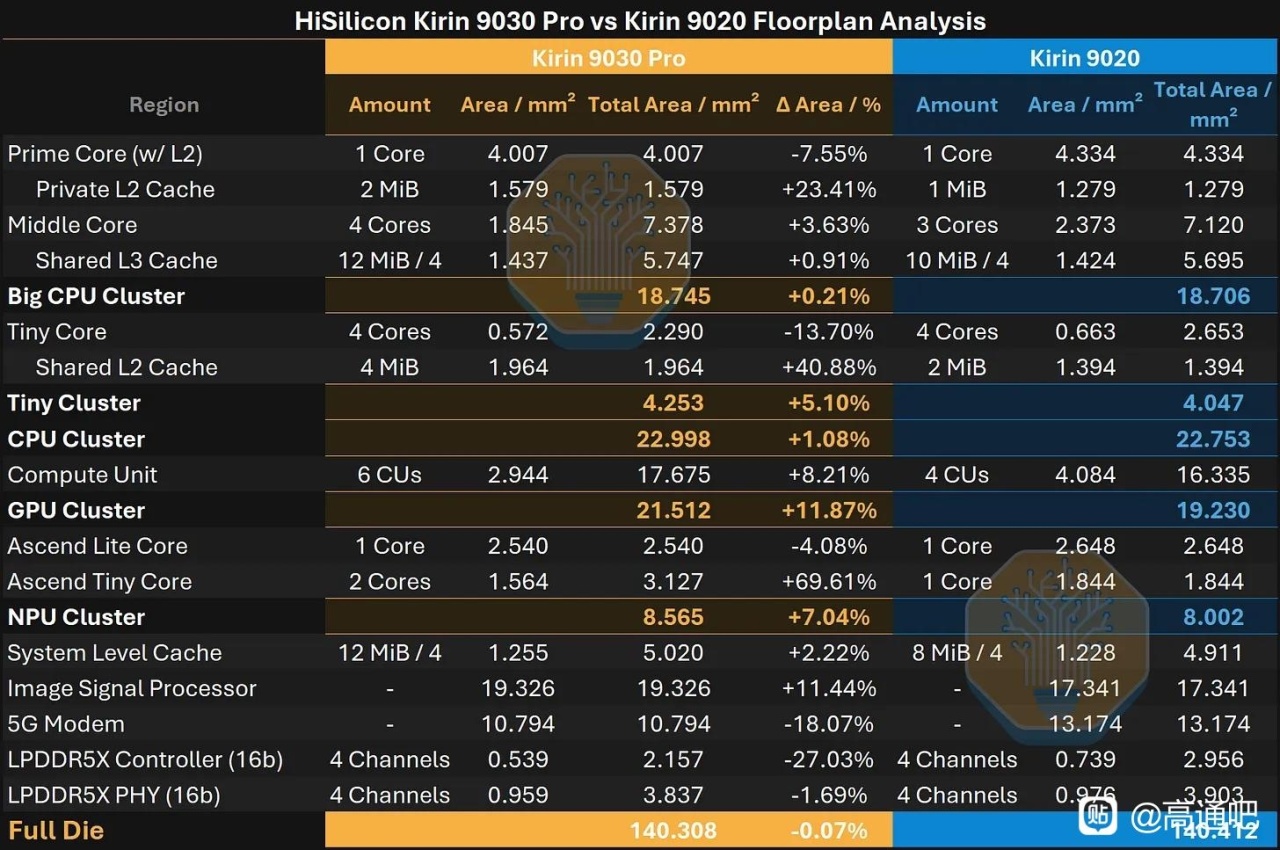
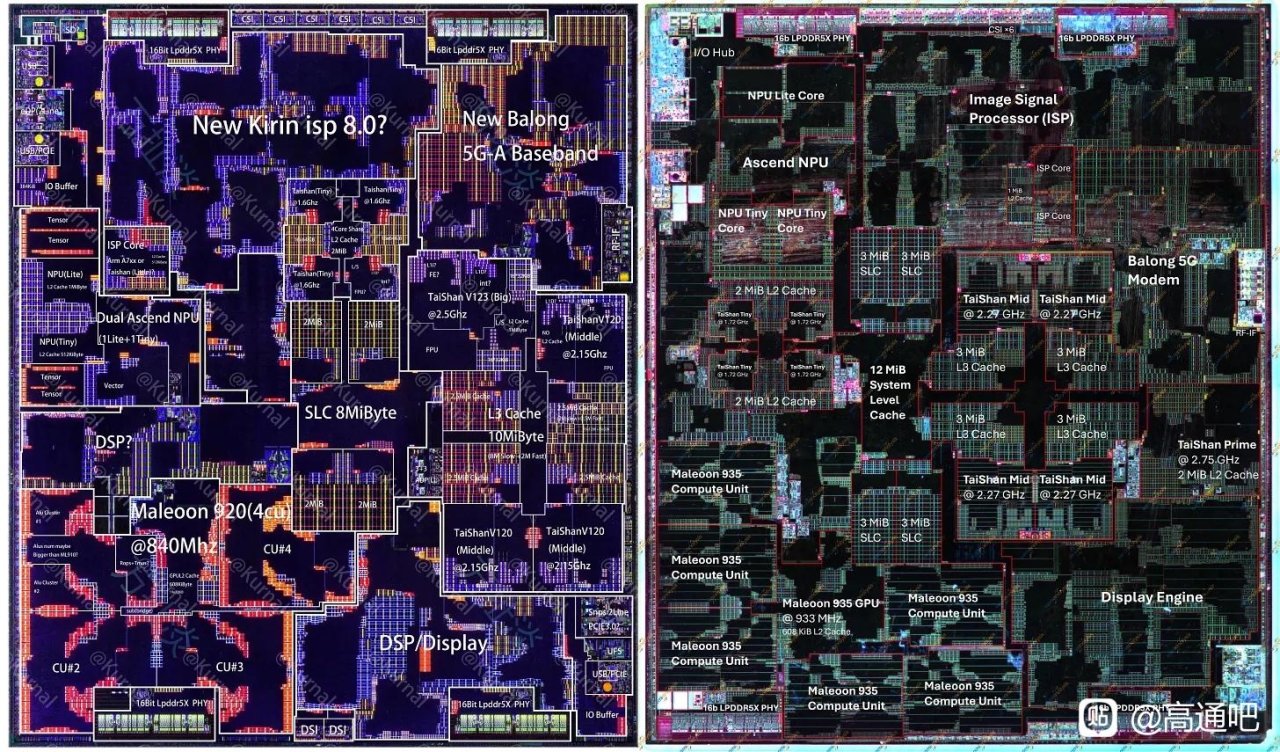
放到 Kirin 9030 上看,N+3 主要带来的是面积预算改善:Kirin 9030 与 Kirin 9020 总 die area 接近,但 9030 能塞入更多中核、更大的缓存、更多 GPU CU 和更大的 NPU 配置。可是 PPA 并没有跟上当前旗舰节点:文章认为 Kirin 9030 大致追到几年前 Android 旗舰水平,GPU/NPU/CPU 都有进步,但效率明显落后于 Apple、Qualcomm、MediaTek、Samsung 的最新旗舰 SoC;原因一是 N+3 本身只到 N6 级密度,二是华为 CPU/GPU 微架构和电压-频率曲线仍落后。
未来路线方面,SemiAnalysis 认为理论上的 N+4 可能继续缩 cell height、CGP 和 M2/M1 pitch,例如 cell height 走向约 198 nm、CGP 到 54 nm,Bohr density 估算可到 137.8 MTr/mm²,接近 TSMC N5/Samsung SF4 级别;但这会把更多层推入 SAQP,mask 数、overlay、工艺窗口都会更痛苦。更远的 N+5 可能需要 backside contacts / backside power 类似思路,才可能到约 163.6 MTr/mm²,但文章判断这不会让它在成本上真正对标领先节点。